2、shedule条件
把并行循环中的计算指定给线程这种方式称为循环队列(loop’s schedule)。对于并行循环中并形体计算量接近的情况,使用默认的队列方式是最优的。但也存在并行循环中每个并行计算量大小不一致的情况,如果计算量大小差距很大,并行程序的执行时间是以最后完成的那个线程为结束标记的,所以如果还采用相同的队列方式,计算量小的线程会先执行完,然后等计算量大的线程执行完,最后才结束并行。在这种情况下,队列分布的不均将会影响整个并行的运行效率,因此,需要去设置其队列选项来控制队列的分布。
schedule条件的格式如下:
schedule(type[,chunk])
其中type有static,dynamic,guided和auto四种,chunk是表示一个并行块的大小。如果需要对1000个循环进行并行,可以将它分成8个并行块(chunk),每个并行块就包括125个循环,则并行块的大小就是125,即chunk size。线程执行的具体对象就是这些并行块chunk。static表示静态分割并行块,在整个并行计算过程中并行块的大小都一样。dynamic则表示动态分割,默认其并行块尺寸为1。guided表示向导性的分割,指定第一个并行块的大小,后面每个并行块的尺寸都会递减,直到最小的并行块尺寸。采用auto或runtime时,不需要设置chunk参数,此时队列类型将由环境变量omp_schedule来控制。
循环结构并行队列过程以及在CPU中执行队列过程如下图所示:
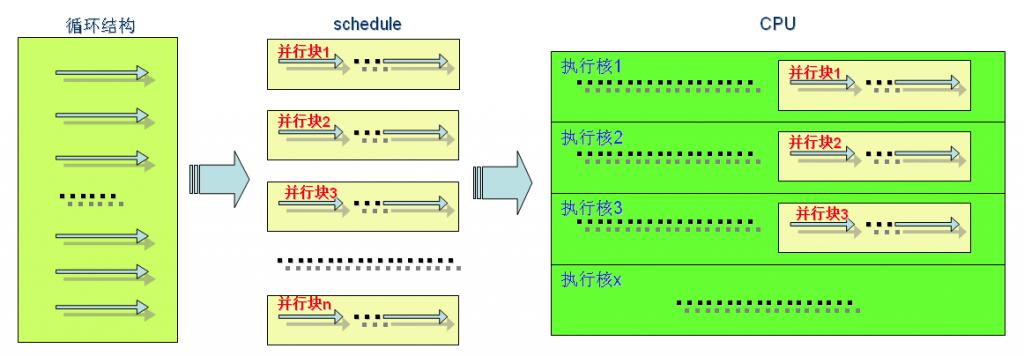
若循环结构中循环次数为100次,通过schedule队列指定每块尺寸为20(即20个循环),则有5个并行块,每个并行块中并形体(一个循环)仍然按串行方式排列。每个并行块对应一个新的线程。若计算机CPU具有4个执行核或4线程,那么每一时刻最多只能执行4个线程,而现在有5个并行块,所以最多只能执行4个并行块,剩下一个并行块就只有在后面,并行计算所耗时间是由最慢的那个线程(并行块)来决定的,所以尽量让这些并行块数目是计算机CPU核心的倍数(1倍或其它整数倍),以充分利用计算机CPU资源。
下面通过一个程序动态设置并行块大小来测试对计算效率的影响,代码如下:
// File: ScheduleTest.cpp
#include "stdafx.h"
#include<omp.h>
#include<iostream>
using namespace std;
//private测试
int ScheduleTest()
{
cout<<"ScheduleTest输出:\n";
inti=0,j,chunkSize = 1;
doublestarttime,endtime;
cout<<"请输入并行块的大小(-200):\n";
cin>>chunkSize;
starttime=omp_get_wtime();
#pragmaomp parallel for private(j)schedule(static,chunkSize)
for(i=0;i<200;i++)
{
for(j=0;j<100000000;j++);
}
endtime=omp_get_wtime();
cout<<"计算耗时为:"<<endtime-starttime<<"s\n";
return0;
}
分别设置并行块大小为1、2等,分别测试其计算耗时,结果如下表所示:
|
并行块大小
|
计算耗时(s)
|
并行块数目
|
每核平均执行并行块数目
|
空闲线程数
|
并行块大小
|
计算耗时(s)
|
并行块数目
|
每核平均执行并行块数目
|
空闲线程数
|
|
1
|
7.08998
|
200
|
25.0
|
0
|
24
|
8.57893
|
9
|
1.0
|
7
|
|
2
|
7.2503
|
100
|
12.5
|
4
|
25
|
7.05088
|
8
|
1.0
|
0
|
|
3
|
7.44965
|
67
|
8.3
|
5
|
26
|
7.25465
|
8
|
1.0
|
0
|
|
4
|
7.67307
|
50
|
6.3
|
6
|
27
|
7.45207
|
8
|
0.9
|
0
|
|
5
|
7.09083
|
40
|
5.0
|
0
|
28
|
7.87446
|
8
|
0.9
|
0
|
|
6
|
8.1865
|
34
|
4.2
|
6
|
29
|
8.4484
|
7
|
0.9
|
1
|
|
7
|
7.69326
|
29
|
3.6
|
3
|
30
|
8.17421
|
7
|
0.8
|
1
|
|
8
|
8.57003
|
25
|
3.1
|
7
|
31
|
8.41376
|
7
|
0.8
|
1
|
|
9
|
7.36662
|
23
|
2.8
|
1
|
32
|
8.62639
|
7
|
0.8
|
1
|
|
10
|
8.30294
|
20
|
2.5
|
4
|
33
|
9.14871
|
7
|
0.8
|
1
|
|
11
|
9.01532
|
19
|
2.3
|
5
|
34
|
9.09194
|
6
|
0.7
|
2
|
|
12
|
8.58991
|
17
|
2.1
|
7
|
35
|
9.32059
|
6
|
0.7
|
2
|
|
13
|
7.27074
|
16
|
1.9
|
0
|
36
|
9.5623
|
6
|
0.7
|
2
|
|
14
|
7.70015
|
15
|
1.8
|
1
|
37
|
10.0546
|
6
|
0.7
|
2
|
|
15
|
8.26512
|
14
|
1.7
|
2
|
38
|
10.1078
|
6
|
0.7
|
2
|
|
16
|
8.72735
|
13
|
1.6
|
3
|
39
|
10.248
|
6
|
0.6
|
2
|
|
17
|
9.05444
|
12
|
1.5
|
4
|
40
|
10.472
|
5
|
0.6
|
3
|
|
18
|
9.52952
|
12
|
1.4
|
4
|
50
|
12.572
|
4
|
0.5
|
4
|
|
19
|
10.0843
|
11
|
1.3
|
5
|
80
|
20.2732
|
3
|
0.3
|
5
|
|
20
|
10.5465
|
10
|
1.3
|
6
|
100
|
24.5377
|
2
|
0.3
|
6
|
|
21
|
10.9686
|
10
|
1.2
|
6
|
150
|
36.5224
|
2
|
0.2
|
6
|
|
22
|
11.4323
|
10
|
1.1
|
6
|
200
|
48.5702
|
1
|
0.1
|
7
|
|
23
|
10.2983
|
9
|
1.1
|
7
|
|
|
|
|
|
注:空闲线程指每队列中并行块数目没有填满CPU中总线程,所剩下的空闲线程(实际上这些线程不是空闲的,它可能用于其它程序,在此只是假定空闲以便于比较)。
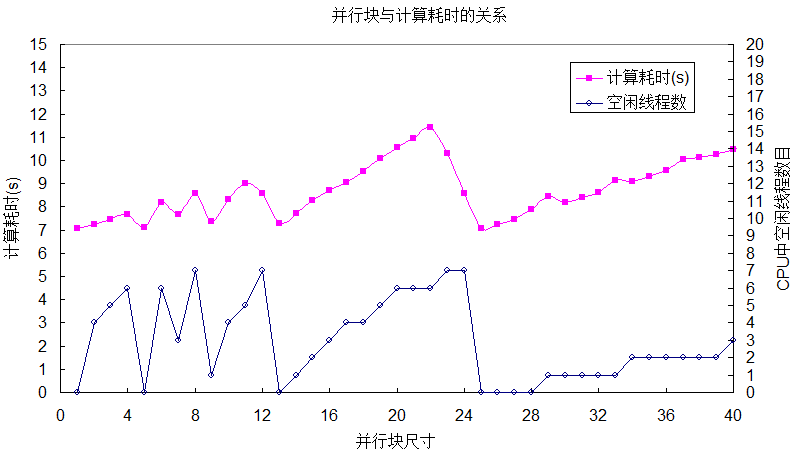
从上图以及测试结果可以得知:在每核平均执行并行块数目大于或等于1.0时,并行块数目对计算效率的影响呈锯齿状形态;当每核平均执行并行块数目小于1.0时,计算效率急剧下降;空闲线程数目越多,计算效率越低。当每核平均执行并行块数目为1,且每个并行块中尺寸均匀相等时,计算效率会提供到极大值,上例中即并行块尺寸为25时。若每个循环的计算量相差不大,建议采用static设置每个并行块尺寸一样。
相关程序源码下载地址:
http://download.csdn.net/detail/xwebsite/3843187
分享到:




相关推荐
labview论坛-事件结构控制多个并行循环运行示例LV8.6版
微机原理与接口技术实验题目及其答案,汇编程序源码,汇编语言分支和循环结构,8255并行接口实验,使用8255完成流水灯实验,8254定时/计数器应用实验,8254 典型应用电路的接法,8259 中断控制器的工作原理, 8259 ...
我们将我们的方法与pthread par allelization进行比较,表明(1)我们的并行执行是确定性的,(2)我们的线程管理缺陷,(3)我们的并行性是隐式的,(4)我们的方法并行化函数和循环。隐式并行性使并行代码易于编写...
第2章为利用parfor对for循环进行并行;第3章为SPMD并行结构;第4章为其他Matlab并行结构;第5章为Matlab并行计算数据类型;第6章为Matlab通用并行程序设计;第7章为MDCE配置;第8章为创建多线程MEX文件;第9章为在...
第2 章为利用parfor 对for 循环进行并行;第3 章为SPMD 并行结构;第4 章为其他Matlab 并行结构;第5 章为Matlab 并行计算数据类型;第6 章为Matlab 通用并行程序设计;第7 章为MDCE 配置;第8 章为创建多线程MEX ...
第2章为利用parfor对for循环进行并行;第3章为SPMD并行结构;第4章为其他Matlab并行结构;第5章为Matlab并行计算数据类型;第6章为Matlab通用并行程序设计;第7章为MDCE配置;第8章为创建多线程MEX文件;第9章为在...
五、循环结构的并行 17 1、范围条件 17 2、shedule条件 22 3、threadprivate指令 24 六、分段并行 25 七、嵌套并行 29 八、OpenMP中的常用函数 33 1、设置线程数目 33 2、获取线程数目 33 3、获取最多线程数目 33 4...
有些时候因为循环次数比较多,我们需要matlab并行处理。 比如用parfor i = 1:10000 end (有很多时候我们想要程序按照i的值从小打到执行) 并行处理中i的值不是顺序的, 所以如果程序突然死掉后也非常麻烦,因为已经...
本书系统介绍涉及并行计算的体系结构、编程范例、算法与应用和标准等。覆盖了并行计算领域的传统问题,并且尽可能地采用与底层平台无关的体系结构和针对抽象模型来设计算法。书中选择MPI(Message Passing Interface)...
计算机体系结构中并行性的发展 1.4.1并行性概念 1.4.2 提高并行性的技术途径 1.5 定量分析技术基础 1.5.1 计算机性能的评测 1.5.2 测试程序 1.5.3 性能设计和评测的基本原则 1.5.4 CPU的性能 1.6...
本文针对部分并行结构的准循环LDPC码译码器,提出了一种将译码准码字存储在信道信息和外信息存储块中的高效存储方法,该方法可减少译码器对存储资源的需求量,并降低了译码电路的布线复杂度;另外,本文通过分析 ...
结构子选板中的While循环和执行过程控制子选板中的While循环用法和作用是相同的,只不过在建立循环结构时有点小差别。 图1 执行控件中的While循环结构 While循环有两个参数:当前循环次数i和条件判断布尔...
主要介绍了C语言中对于循环结构优化的一些入门级方法,包括算法设计的改进来提高一些并行性等方法,要的朋友可以参考下
◆讲解命令式数据并行、命令式任务并行、并发集合以及协调数据结构。 ◆描述PLINQ高级声明式数据并行。 ◆讨论如何使用新的Visual Studio 2010并行调试功能来调试匿名方法、任务和线程。 ◆演示如何对数据源进行...
◆讲解命令式数据并行、命令式任务并行、并发集合以及协调数据结构。 ◆描述PLINQ高级声明式数据并行。 ◆讨论如何使用新的Visual Studio 2010并行调试功能来调试匿名方法、任务和线程。 ◆演示如何对数据源进行...
◆讲解命令式数据并行、命令式任务并行、并发集合以及协调数据结构。 ◆描述PLINQ高级声明式数据并行。 ◆讨论如何使用新的Visual Studio 2010并行调试功能来调试匿名方法、任务和线程。 ◆演示如何对数据源进行...
根据该类LDPC码的准循环特性,提出了一种基于后验概率的简化最小和算法及其对应的半并行译码结构。其可实现在同一接收机中尽量复用硬件资源并减少消耗情况下LDPC码的多码率译码。最后,使用可编程门阵列实现了此结构...
利用一个和扫描链等长的扫描移位寄存器,对传统扫描链进行改造,提出了一种新型的选择触发的扫描链结构。它有效地降低了传统扫描链扫描移位过程中的动态功耗,并提高了扫描时钟频率,同时它所需要的测试数据为原始...
056.while循环结构_死循环处理 057.for循环结构_遍历各种可迭代对象_range对象 058.嵌套循环 059.嵌套循环练习_九九乘法表_打印表格数据 060.break语句 061.continue语句 062.else语句 063.循环代码优化技巧(及其...
循环结构包括For循环结构和While循环结构,两者都可以用来重复执行程序。For循环结构的循环次数相对比较固定,循环过程不能中断,对确定数值循环的程序比较适合;While循环可以添加条件进行控制。 条件结构根据...